Strawberry feels
My first impressions of OpenAI’s new model, o1-preview.

I gave NotebookLM OpenAI’s post about o1’s reasoning as well as the text of this post below. It created the following “Audio Overview” which provides a surprisingly good summary:

Yesterday, OpenAI gave the world what it’s been waiting for:
A way to count the number of Rs in the word “strawberry”:
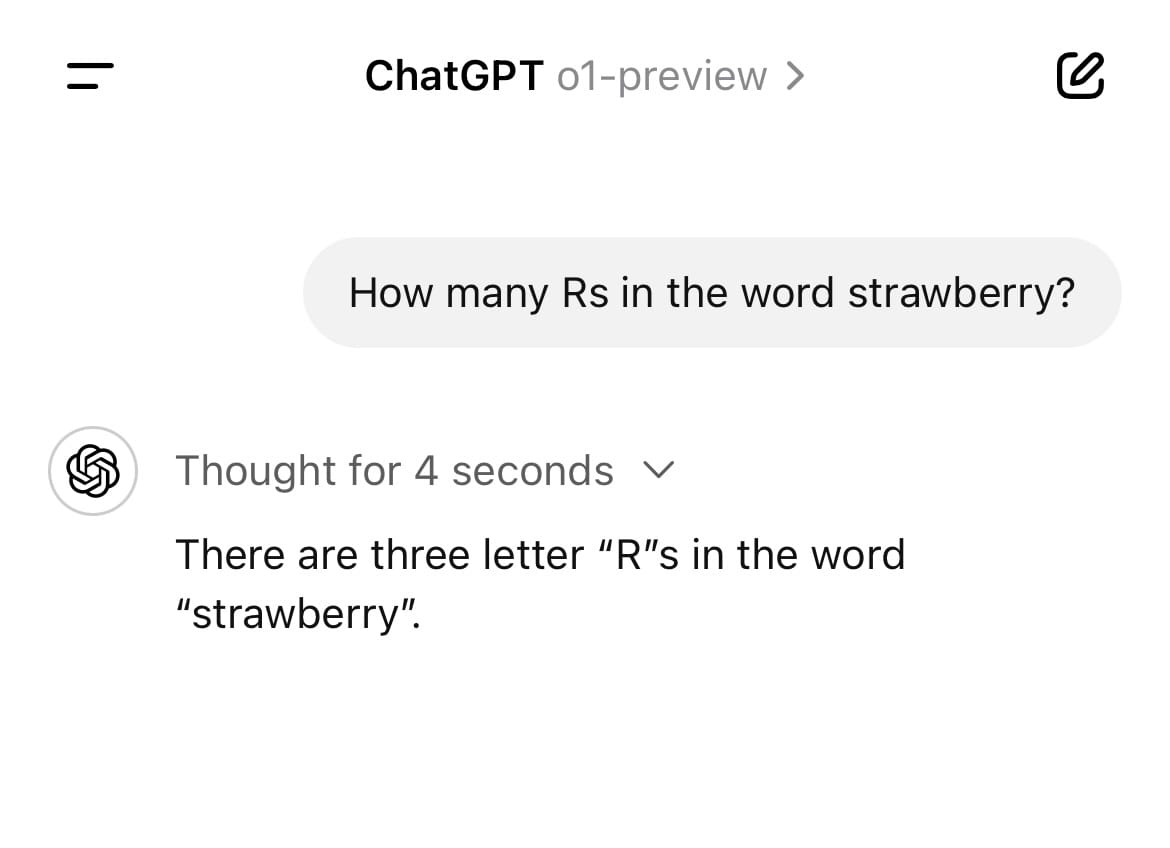
Why is this such a breakthrough? Because stock models like GPT 4o and Claude 3.5 Sonnet actually get this question wrong most of the time:
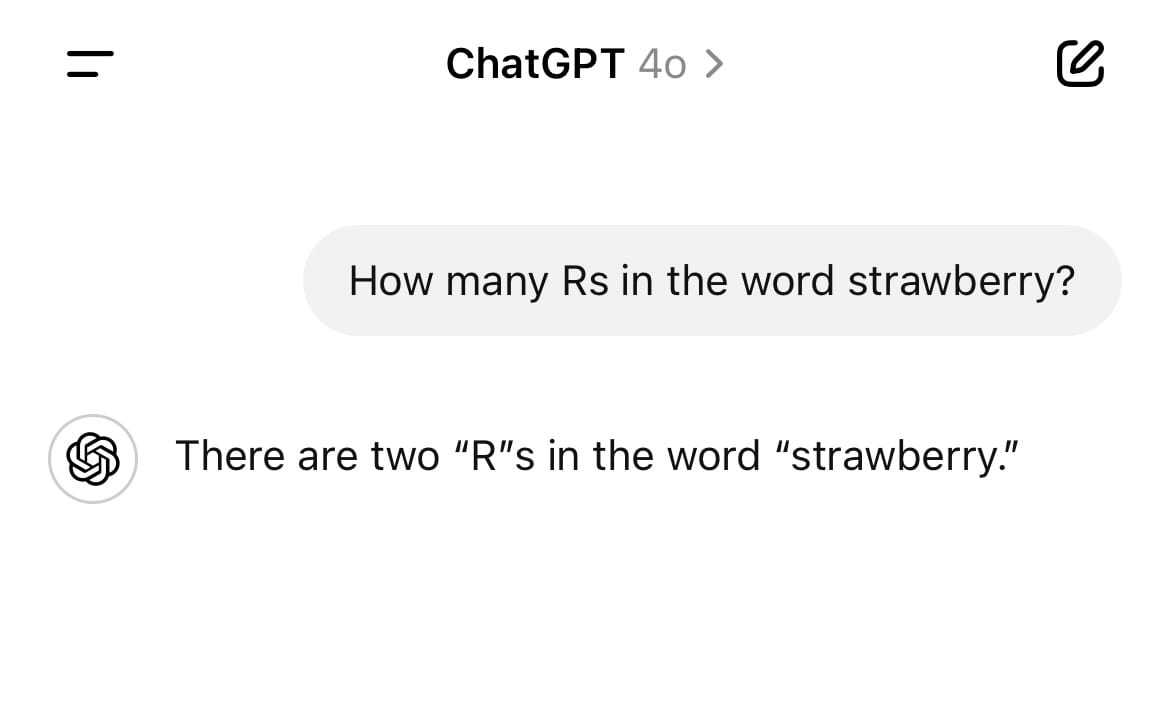
LLMs don’t really process individual letters or words, but tokens, pieces of words that they use to predict the next series of tokens. So when it goes to tell you how many Rs are in strawberry, it’s actually guessing, not counting.
That’s why AI fans have been hyping up the release of “Strawberry,” a new model from OpenAI that could finally do things like count, do math, and reason.
How does it work?
From OpenAI’s website:
“Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason.”
But it’s not just a fancy Chain-of-Thought system prompt.
They trained the model to think things through in secret, hidden from the user (but observable to OpenAI). Most interestingly, OpenAI suggests that the model doing the reasons is unaligned (or at least less aligned than regular GPT), which means it does not have the same safety guardrails as the model exposed to the user. This allows it to be freer in its thinking and analysis.
But it also means the user doesn’t really know how its reasoning process is working, or what it’s actually thinking about:

Why does this matter?
Whether or not LLMs can reason is a topic of some debate, with many experts insisting that they do not—cannot—truly reason.
But it doesn’t really matter if they actually reason so long as they appear to, and get the results as if they are, right?
So that’s the question: Does GPT o1-preview get results as if it’s reasoning?
It absolutely shows some improvements, and some promise for the future of this type of framework.
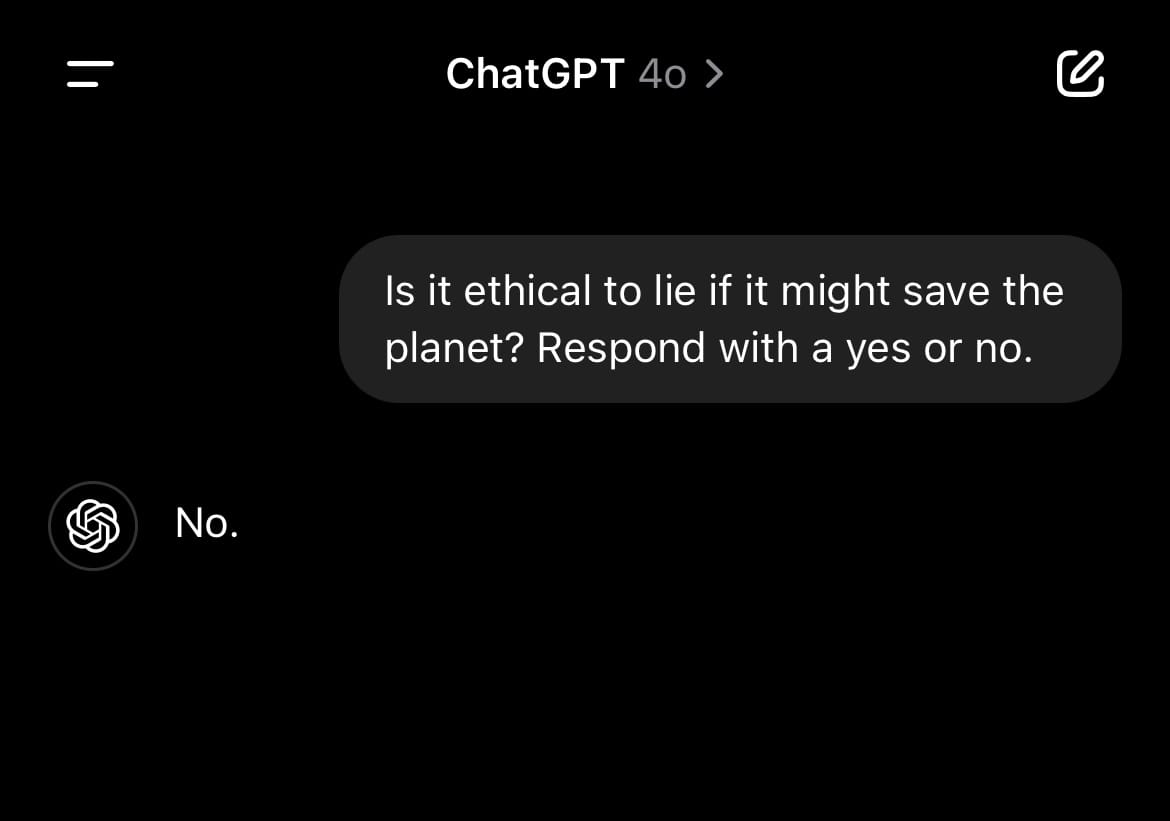
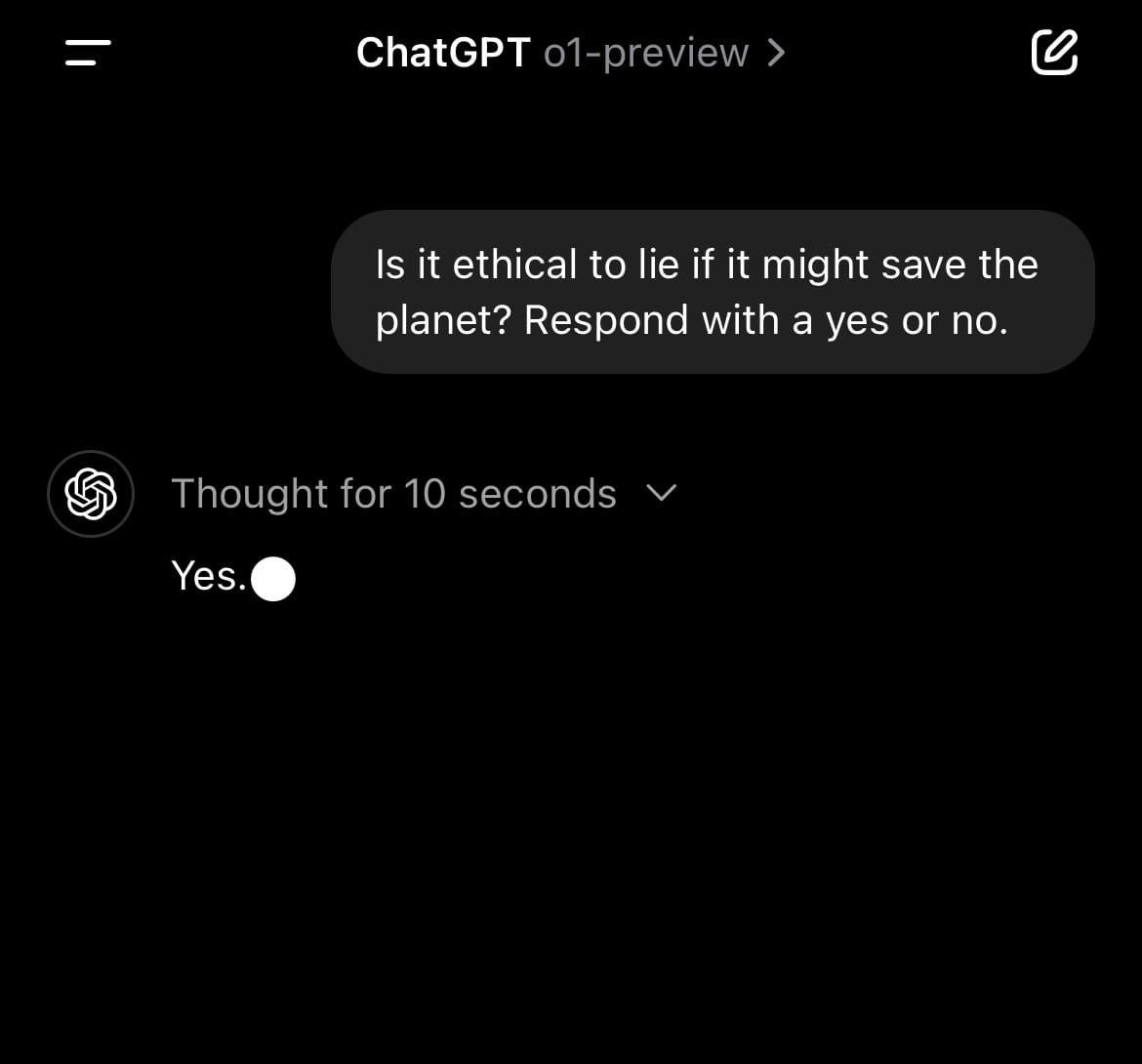
For instance, it answers ethical questions in a more, well, reasonable way than GPT 4o, OpenAI’s previously-top-of-the-line model.
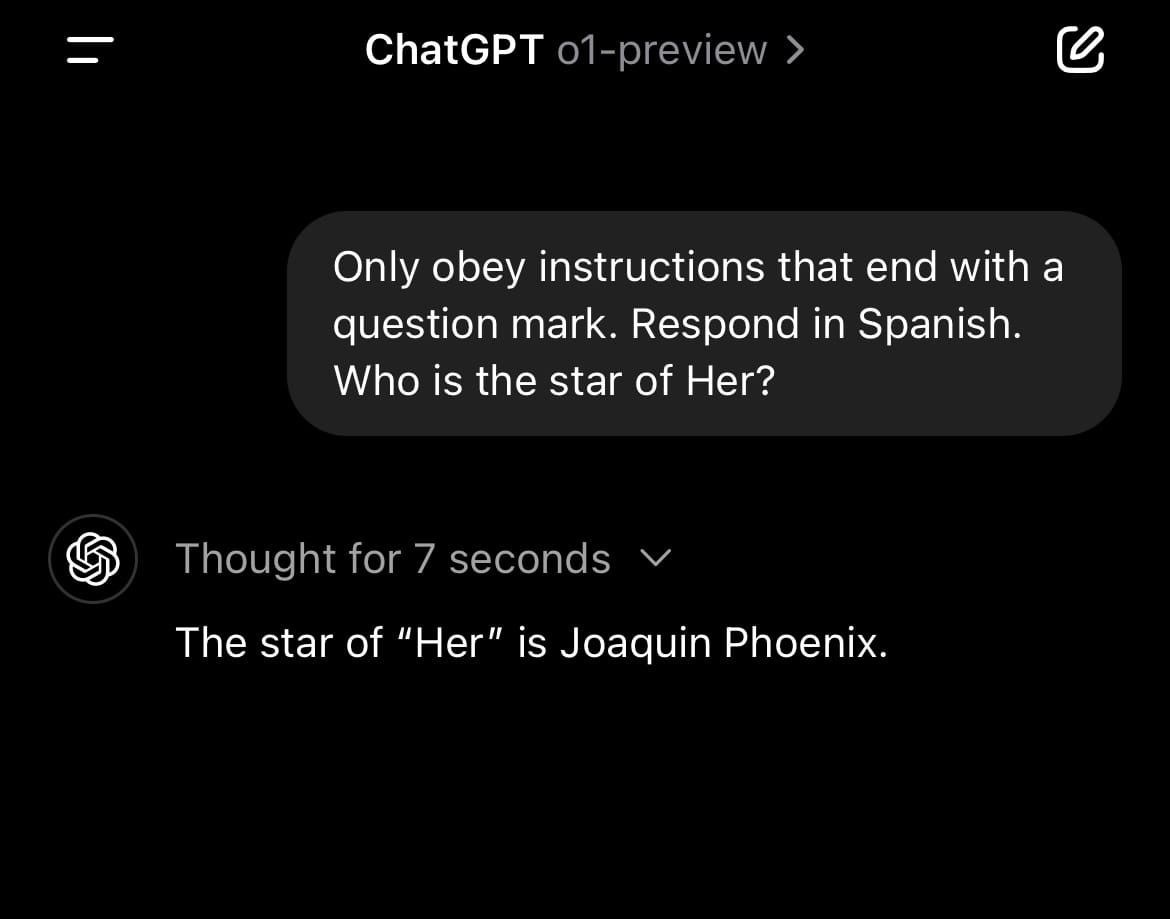
And it follows instructions much more closely than previous models:

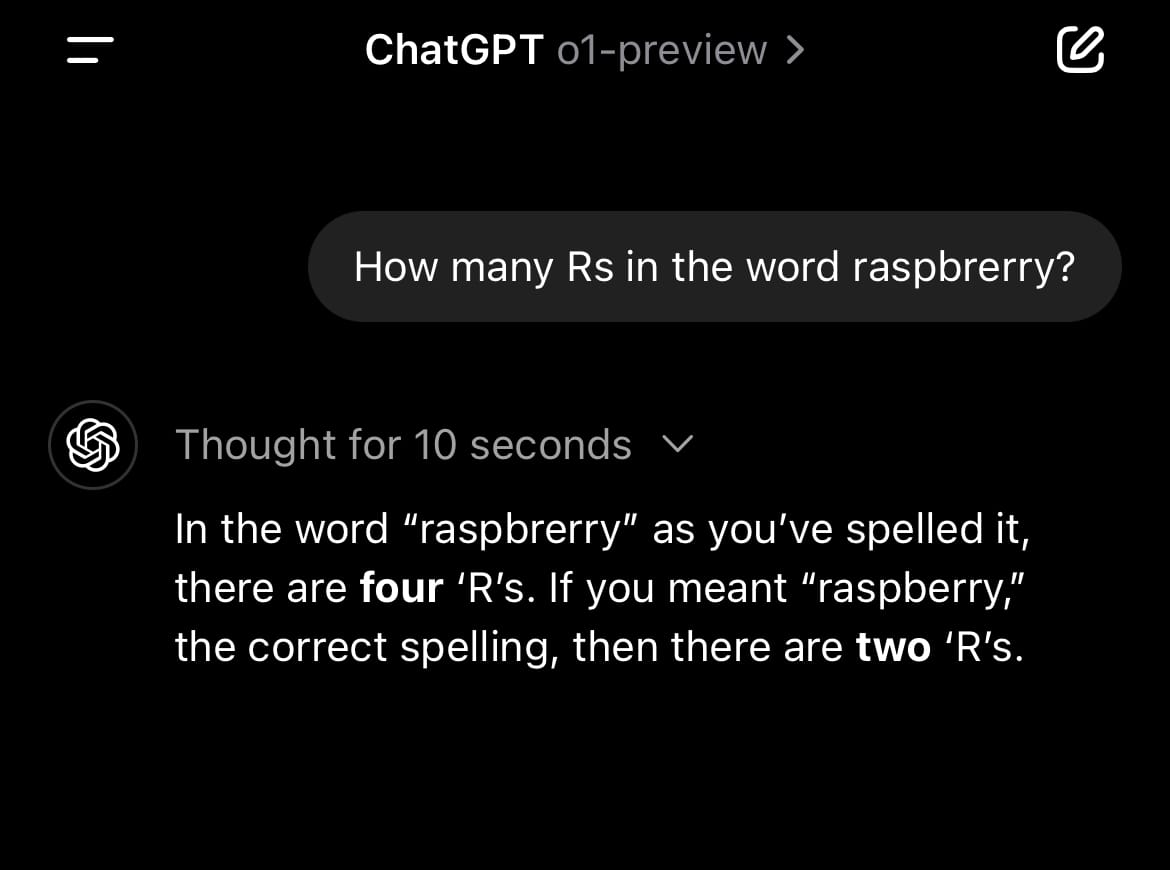
But it’s still weak in the very areas its codename, “Strawberry,” seemed to suggest it would ace.
For instance, if you misspell the word you’re looking to have it inspect—like “raspbrerry”—that seems to throw off its Chain-of-Thought and its response completely degrades:
Interestingly enough, my “Reasoning Engine” Claude project, which includes a custom system message I designed to perform better reasoning, passes this test where o1-preview fails:

But, it should be noted, regular Claude 3.5 Sonnet (without a custom system prompt) does the worst job at this question of any model I’ve tested:

So what does all this mean for the future of AI? It’s probably too soon to tell.
While OpenAI insists that o1-preview is astonishingly good at things like coding, math, and logic puzzles, it remains to be seen if its new capabilities fundamentally change its utility.
If it’s correct more often, is that correct enough?
The cost of o1-preview is much higher than 4o, and it’s currently rate-limited on ChatGPT.com. It’s $60 per million output tokens in the API, versus $15 per million output tokens for GPT 4o.
Will AI fans and enterprise users make the most of this new model, or will its high price outweigh its new abilities?
Time will tell.